The Mirage of AI ROI
Part 2 of 3: Why the Business Case for Enterprise AI Is Built on Sand

The Thesis: AI ROI models measure the wrong unit. They price tokens; enterprises pay for outcomes under constraints.
The Constraint: Generation costs deflate aggressively. Verification costs amortize poorly in consequence-bearing domains. This “Markov Tax” inverts expected economics wherever errors have consequences.
The Implication: Current business cases conflate inference deflation with enterprise TCO, ignore failure-heavy pilot portfolios, and treat governance as overhead rather than cost of goods sold.

Enterprise AI is being sold with the confidence of a utility and priced with the behavior of a land grab.
That mismatch breaks ROI before a single model is deployed.
Most ROI narratives treat AI like a deterministic software upgrade: drop it in, compress cycle times, reduce headcount, move on. What is actually being introduced is a probabilistic operating regime—new cost structures, new failure modes, and a governance surface that resembles less a “tool” than a new category of actor inside the business.
The outcome is predictable: decks full of “transformative value” and a quiet refusal to interrogate the denominator.
What the Believers Have Right
Before diagnosing the fallacy, acknowledge what the believers have right.
The cost curve is violent. Stanford’s AI Index documents a 280× drop in inference cost for GPT-3.5-equivalent performance between late 2022 and late 2024, with task-dependent declines ranging from 9× to 900× per year. This is what computation does. The slope will continue.
Open-weight models are closing the gap. The same AI Index reports open-weight models narrowing performance differences with closed models on key benchmarks. Self-hosting and multi-provider strategies become more credible, not less.
In some domains, productivity uplift is measurable. Field evidence shows GenAI assistance improving call-center productivity by approximately 14%, with benefits concentrated among less-experienced workers. Developer productivity studies show meaningful gains in controlled settings. These are real effects in specific contexts.
The labor arbitrage spread is large. In bounded domains, the cost differential between human and agent can be 1,000% to 10,000%. Even with 30% failure rates requiring human review, the 70% autonomous throughput is achieved at pennies on the dollar.
So yes: costs are dropping, models are improving, labor arbitrage exists, and certain use cases are already positive.
The problem is what happens when that truth gets generalized into a business case template.
Where ROI Is Already Repeatable
The critique is not that ROI doesn’t exist. It does—in bounded domains:
Copilot augmentation in high-volume knowledge work: support triage, compliance drafting, QA review
Search and classification over enterprise corpora where error cost is bounded and human review is efficient
Developer productivity in controlled environments—large fractions of developers now use AI coding tools daily, with double-digit velocity gains reported in controlled studies
The mistake isn’t that local wins are fake. It’s that they’re being priced like enterprise transformation. The 14% call center uplift does not port to legal review, clinical decision support, or financial modeling. Specificity is the enemy of the template.
The Meter Is Wrong
Here is the economic problem most ROI models elide: the spreadsheet prices tokens; the business pays for constrained outcomes.
This is basis risk. The metered unit is not the economic unit.
The DeepSeek moment made this vivid. Frontier-level inference at $0.14–$0.55 per million tokens. Training costs a fraction of Western incumbents. The market concluded: intelligence is becoming free.
The conclusion is half-right. Raw inference is commoditizing. But the enterprise doesn’t purchase tokens—it purchases outcomes with constraints: auditability, reversibility, authorization semantics, evidentiary trails, policy compliance, tail-risk containment.
Those constraint-bearing layers remain labor-, integration-, and liability-shaped. They don’t follow exponential cost curves.
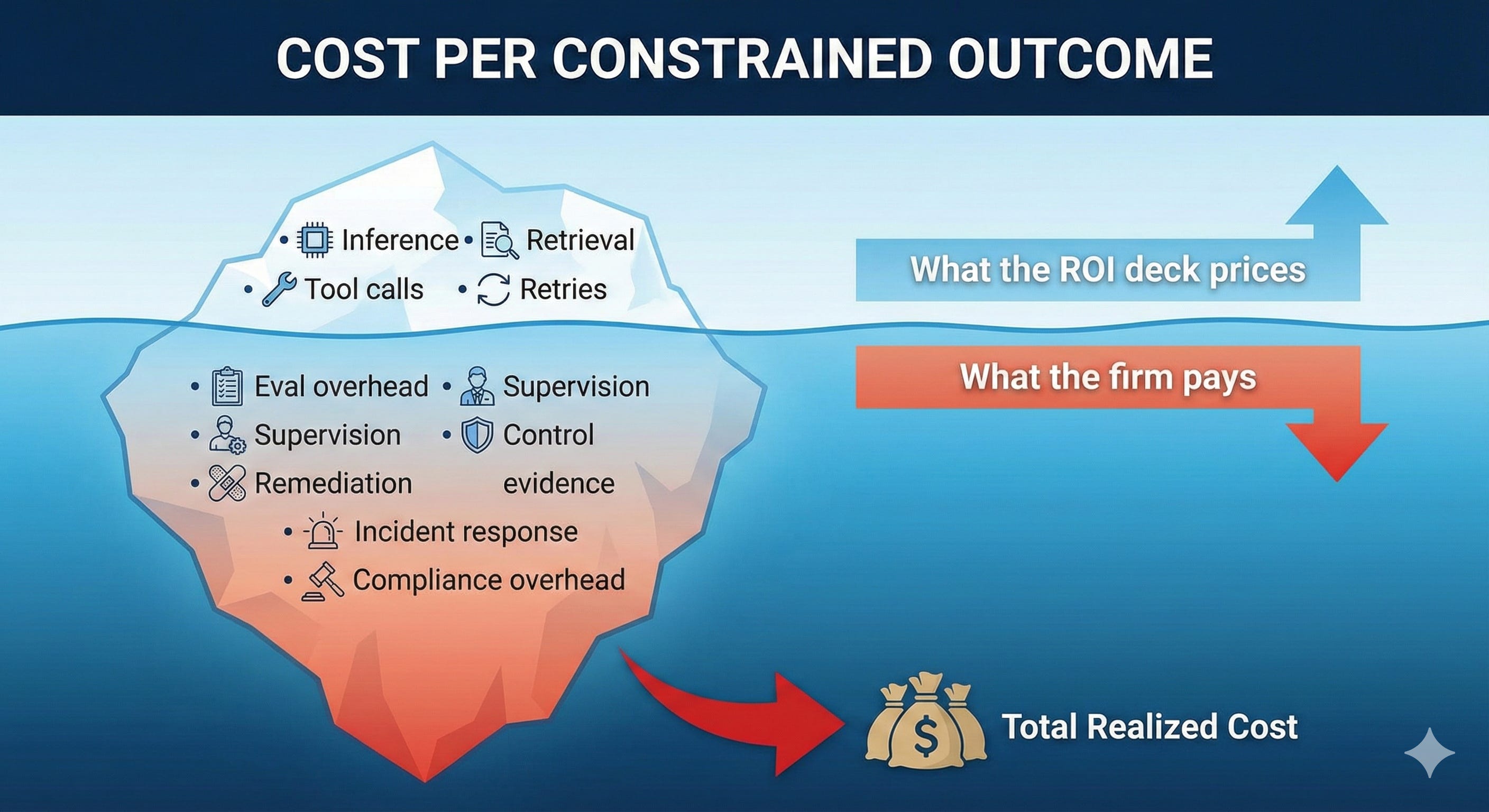
Even if raw inference deflates to near-zero, wrappers monetize constraints: governance features, workflow products, risk controls, seat models, bundles, commitments, indemnities.
Anthropic introduced rate limiting after users consumed tens of thousands in model usage on flat-rate subscriptions. OpenAI signaled that ChatGPT Plus at $20/month may be unsustainable. The pattern is clear: prices rise at the product layer even as raw inference costs decline.
The subsidy is being withdrawn. The meter was always wrong.
Even if underlying inference continues to deflate, enterprises should assume pricing will migrate upward into the constraint-bearing layers: guarantees, governance, latency, indemnities, and integration. The margin moves; it doesn’t disappear.
The FinOps Reckoning
The organizational mechanism that will enforce this reality is already emerging: FinOps, chargeback models, and hard consumption quotas. When AI spend hits a budget line with an owner—rather than floating as “innovation investment”—the gap between token optimism and outcome economics becomes visible. Governance stops being philosophy and starts being a P&L constraint.
The Consumption Trap
The counterargument: cheap inference solves the economics.
The opposite is true.
Jevons Paradox holds. When a resource becomes more efficient to use, total consumption increases rather than decreases. Enterprises aren’t consuming less—they’re consuming orders of magnitude more: chain-of-thought reasoning, majority voting, agentic loops, retries.
If document processing scales from 1,000/day to 1,000,000 because inference is cheap, the verification burden scales by 1,000x. Human review doesn’t follow exponential cost curves.
Cheap inference doesn’t solve the governance problem. It floods the enterprise with “plausible but unverified” faster than any human process can absorb. The Markov Tax becomes the hard ceiling on ROI.
The second-order effect: verification becomes a new labor market—QA, reviewers, model risk analysts, audit evidence production, red-teaming—and wages rise in exactly the places enterprises assumed AI would eliminate cost.
The Production Cliff
The portfolio baseline is failure-to-production. Ignoring it is incomplete accounting.
MIT research frames it bluntly: despite $30–40 billion in enterprise GenAI investment, 95% of organizations report zero return, and only 5% of evaluated systems reach production. IDC’s numbers point the same direction: 88% of AI proofs-of-concept never reach widescale deployment. Gartner reports enterprises routinely abandon a significant portion of AI pilots before production.
The counterargument is that this is a lagging indicator—the 1996 of AI. Tooling will mature. Success rates will invert.
Partially true. But the tooling problems are the smaller fraction. The larger fraction is organizational: accountability gaps, integration complexity, incentive misalignment, governance structures that can’t make cross-silo decisions. These are the same failure modes that have plagued ERP implementations and data warehouse projects for 30 years. AI doesn’t solve organizational dysfunction; it amplifies it.
Even if the percentages are debated, the distribution is not: lots of pilots, few production systems with durable ownership, evals, and change control.
Firm-level ROI is a weighted average across abandoned pilots, partial deployments, a handful of scaled wins, and the organizational cost of running the experiment factory. If failure rates aren’t modeled, ROI isn’t analysis. It’s fan fiction with numbers.
The Operating Model You Didn’t Budget For
AI drags in a structural cost layer that most ROI templates omit:
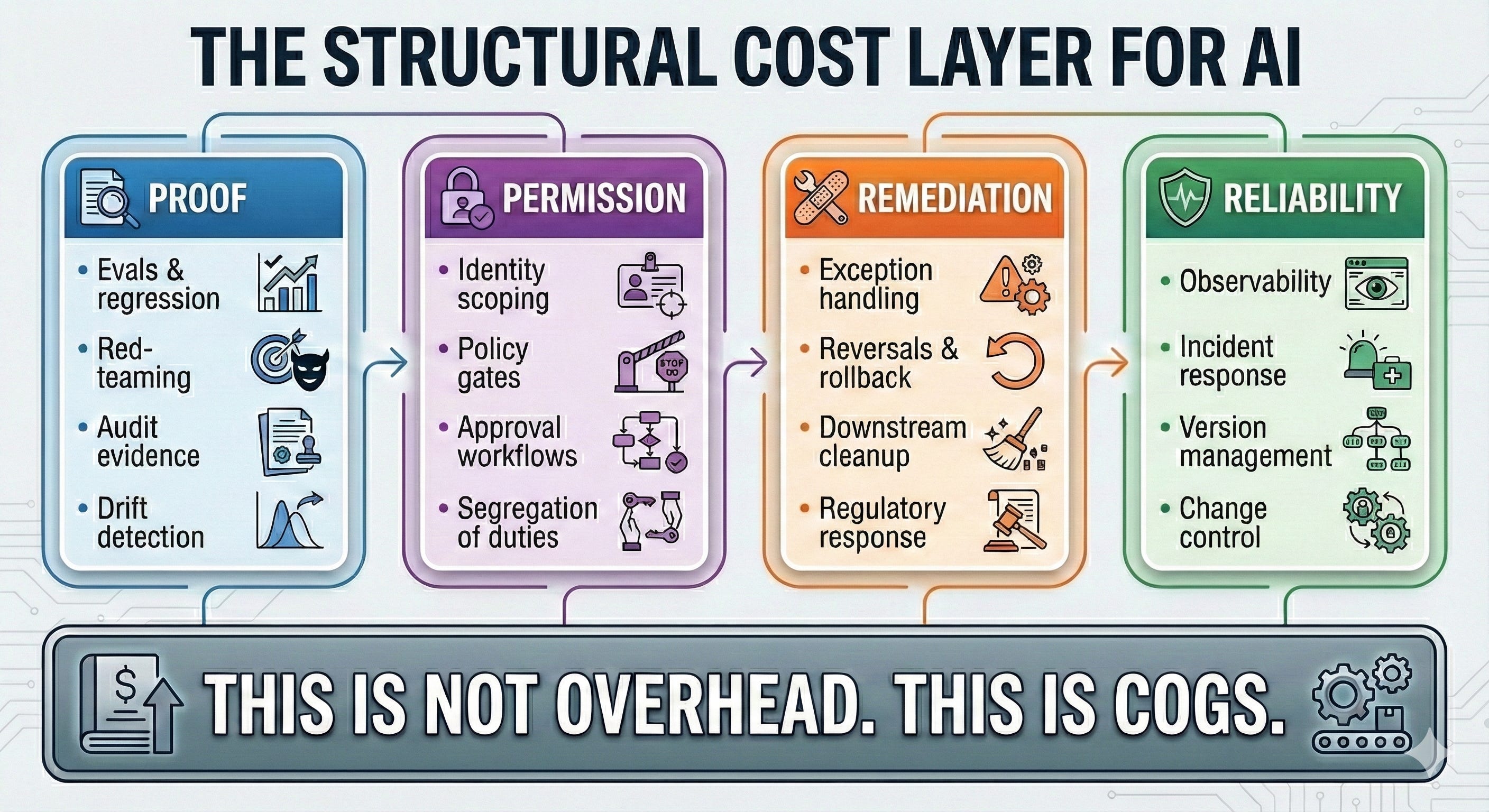
Verification can be partially automated—evals, synthetic tests, policy checking. The tooling is maturing.
Accountability cannot be automated. Who signs. Who is liable. What evidence is produced. What the regulator accepts. “The model evaluated itself” is not a legal defense.
Verification includes legal defensibility and disclosure integrity. The SEC has already charged firms for “AI washing”—misleading claims about AI capabilities. EU AI Act enforcement begins August 2026, with major provisions including obligations for general-purpose AI systems. These are not thinkpieces; they are compliance calendars. The cost of producing audit-ready evidence for probabilistic systems is now a recurring line item, not a one-time implementation fee.
In AI, reliability and governance are not accessories. They are recurring cost of goods sold.
The Agentic Amplifier
Agentic AI is the newest amplifier of the ROI fallacy because it invites the laziest translation in enterprise history:

Industry signals are unusually aligned. Gartner forecasts over 40% of agentic projects will be canceled by 2027 due to cost, unclear value, and risk control gaps. Fewer than one in eight enterprises actually run agents in production.
Here is the key correction:
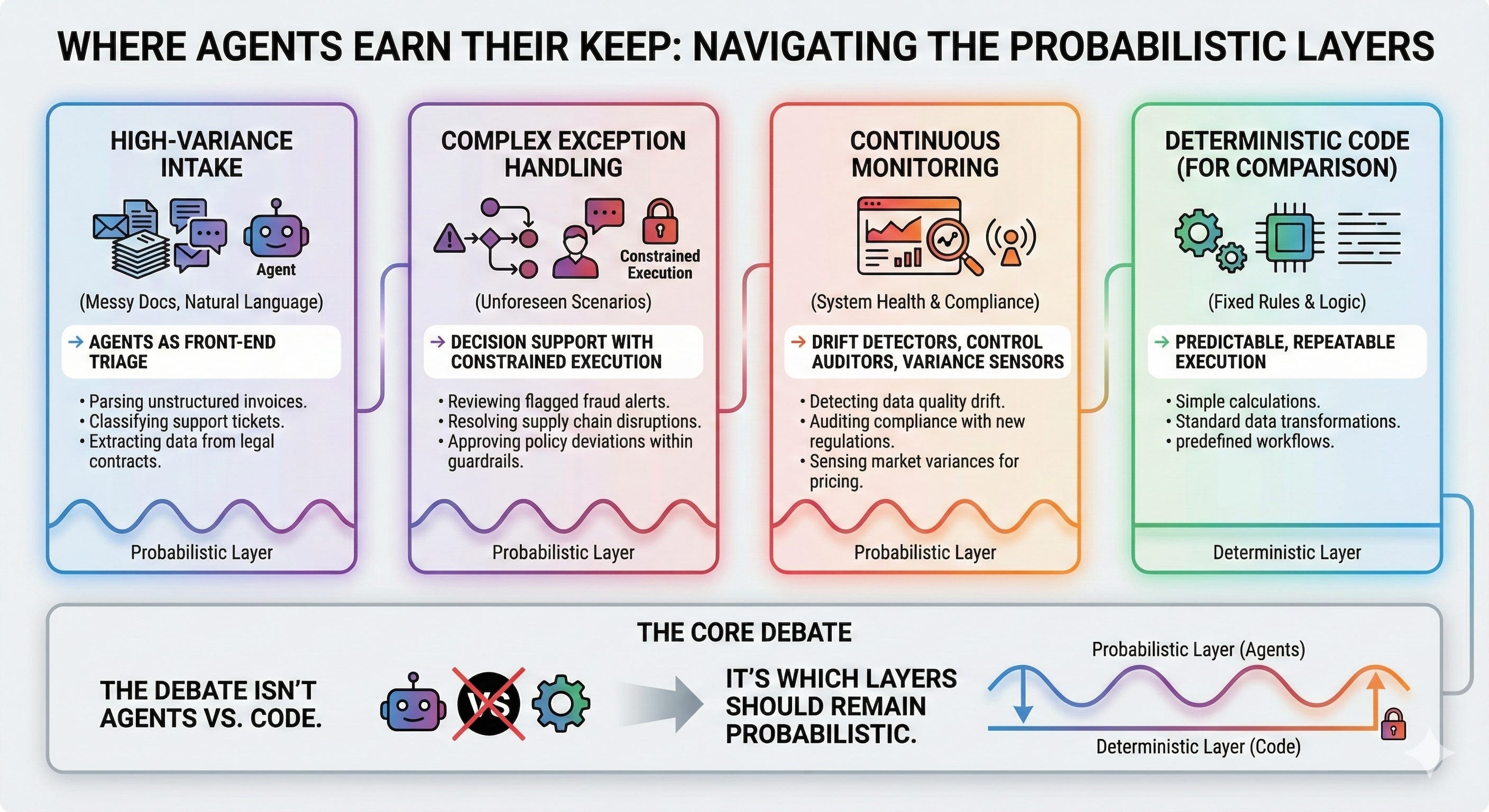
At enterprise scale, agents rarely substitute labor cleanly. They substitute certainty with orchestration.
The labor arbitrage exists—the spread between silicon and carbon is real. But the arithmetic collapses when you measure the wrong unit.
The unit is not “cost per agent-hour.” It is: cost per correct outcome under constraints, including tail risk.
In enterprise workflows, the cost of errors can dominate compute: financial mispostings, entitlement mistakes, compliance violations, customer-impacting failures, audit exceptions requiring remediation programs. The 30% failure rate is not “30% needs review.” It’s often “30% creates downstream cleanup with nonlinear cost.”
If thirty minutes of a competent operator is replaced with an agent that burns compute through orchestration, retries, tool calls, and approvals—and still needs a human to validate—you did not create ROI. You moved costs from payroll to compute, governance, and remediation.
Sometimes that trade is still worth it. It does not automatically create ROI.
The mistake is not agents. It’s unpriced tail risk.
The Translation Layer
Most “legacy” talk is lazy. It treats anything old as drag and anything new as progress.
The reality is that a large class of so-called legacy systems are not obsolete technology. They are the enterprise’s immune system—existing to preserve accountable truth.
Modern enterprises run on systems that encode hard-won constraints: approval sequencing, segregation of duties, change windows, ownership checks, reconciliations, audit trails. Those controls are not bolt-ons. They are part of the workflow grammar. They are why the system is trusted.
Immune systems can become autoimmune. Controls that preserve truth can also throttle throughput. The goal is programmable immunity: preserve constraints while compressing friction.
But there’s a separate category: true legacy footprints—mainframe, midrange, batch interfaces, proprietary protocols, stateful procedures. This is not immune system; this is geology.
Agents can’t wrap around timing assumptions and implicit state. Modern orchestration assumes idempotent calls, explicit state, observable outcomes. Legacy systems frequently embed state transitions in procedural sequences where “step 3 failed” doesn’t mean “nothing happened.” It means “something happened and you don’t know what.”
Agents amplify this because they explore and retry. The system interprets retries as duplicate business actions. You just invented double-billing, duplicate orders, phantom entitlements—at machine speed.
We’ve seen this movie before. RPA promised to automate across brittle applications by mimicking the human path. It worked in narrow, stable, well-bounded workflows. It became fragile under UI change, exception variance, and upstream drift. It scaled brittleness when used as a substitute for modernization.
Agentic orchestration repeats the temptation with better marketing and a bigger blast radius.
What enterprises actually build is not an “agent layer.” They build a translation layer: policy gates, intent validation, reversible execution, human-readable justification, evidence capture.
Call it boring. It’s the immune response. Agents don’t repeal physics.

For AI Platform & Product Leaders
If deals are stalling in pilot purgatory, the verification asymmetry explains why. You’re selling tokens. The customer is buying outcomes.
The product opportunity is the constrained-outcome layer:
• Evals and regression as product features, not customer problems
• Policy enforcement built in, not bolted on
• Audit evidence as default output, not optional logging
• Rollback as architectural primitive, not afterthought
• Pricing aligned to outcomes, not token volume
Vendors selling “autonomy” without constrained execution will churn.
Vendors selling constrained outcomes will become infrastructure.
The Stress-Tested Thesis
The critique is not that AI cannot create value. It can. The labor arbitrage is real. The cost curve is real. The productivity gains in bounded domains are measurable.
The critique is that ROI decks are measuring the wrong unit.
Inference deflates; enterprise TCO does not deflate at the same rate. The enterprise isn’t buying tokens—it’s buying outcomes with constraints. The constraint-bearing layers are where cost volatility lives.
Portfolio baselines assume success; reality is failure-heavy. Pilots are cheap; production is expensive. Ignoring the denominator isn’t optimism; it’s incomplete accounting.
AI introduces recurring operating costs that behave like COGS, not one-time implementation. Reliability and accountability are permanent line items.
The labor arbitrage exists, but the unit matters. Cost per agent-hour obscures cost per correct outcome under constraints, including tail risk.
The ROI mirage is not conspiracy. It’s the predictable result of applying consumer-tech logic to enterprise-grade constraints—the same category error that produces cargo cult adoption of every paradigm mistaken for a strategy.
The question is not whether AI creates value. It can, and it does—in specific domains with measurable effects. The question is whether the enterprise can capture that value without building the firm on probabilistic debt.
The business case for AI, as currently constructed, conflates inference deflation with enterprise TCO, ignores the pilot-to-production cliff, and measures the wrong unit entirely. That’s not a technology problem. It’s an accounting problem—and accounting problems eventually become balance sheet events.
Part 3 offers the prescription: how to use AI as scaffolding for transformation rather than as permanent, ungovernable substrate.